

Frontier Systems Technical Paper
Company-Led Technical Preprint / Technical Disclosure Version
Version 1.0 | 2026
RR-Gov™ RDIS: A First-Definition-Type Governance-Readiness Framework for Regulated Deployment of Embodied AI Eldercare Robotics
Hon Hsiang Ong1, Xin Zhao1, Wentao Zhao1, Wenqun Guo1, Qiang Huang1, Weijie Tan1, Tingting Shen2, Tian Shen1, Chunqiu Yan2, Jian Zhang1*
1AJJ Healthcare Management Pte. Ltd., Singapore.
2Hangzhou Huaxi Intelligent Technology Co. Ltd., Hangzhou, China.
Correspondence: zhangjian@ajjmedtech.com.sg
Important Notice
This document is a company-led technical preprint / technical disclosure version prepared for transparent disclosure, public reference and subsequent scholarly discussion. It has not yet undergone independent peer review and should not be interpreted as a peer-reviewed journal article, final published paper, regulatory approval, clinical validation, government endorsement, institutional endorsement, investment recommendation, sales forecast, staffing-reduction authorisation or evidence of universal deployment readiness.
Publication and Evidence Boundary
This AJJ Research technical preprint / technical disclosure is intended to preserve a citable, time-stamped public version of the RR-Gov™ / RDIS framework for company website posting and DOI registration. The RDIS demonstration score and related evidence materials should be read as anonymised, aggregated and boundary-conditioned technical disclosure, not as formal journal peer review, regulatory approval, clinical validation, product clearance, institutional endorsement, investment recommendation or evidence of universal deployment readiness.
Prior Public Version and Future Journal Submission Boundary
This public version may be further developed into a substantially revised manuscript for peer-reviewed journal submission. Any subsequent submission should disclose this public version and URL/DOI in accordance with the target journal policy. For journal submission, the manuscript should retain additional scholarly value, including full standards anchoring, methodological explanation and transparent disclosure of this prior public version.
Abstract
This paper proposes RR-Gov™, a socio-technical governance-readiness framework for assessing whether embodied AI eldercare robots can be considered supportable for regulated institutional deployment. Existing studies have examined socially assistive robots, long-term care robotics governance, implementation barriers, robot ethics, healthcare AI translation, public-health data ethics, algorithmic auditing and model reporting [1–10]. However, these streams do not yet provide an integrated, weighted and stage-gated model that converts institutional deployment readiness into auditable system evidence for embodied AI eldercare robots. RR-Gov™ addresses this gap through the Regulated Deployment Infrastructure Score (RDIS), an early integrated and first-definition-type assessment language for the intersection of embodied AI, eldercare robotics, institutional health systems, auditability, data governance and regulated deployment readiness. RDIS combines adjusted governance risk, compliance confidence, AI auditability, institutional deployability, data governance and governance-adjusted viability. Critical stage-gates prevent commercial, operational or adoption strengths from offsetting unresolved safety, compliance, auditability, data-governance or human-oversight weaknesses. To keep the technical paper readable for public reference and future peer review, the paper retains the overall RDIS architecture, composite formula, evidence logic, demonstration result and interpretation boundary, while detailed formula definitions, scoring rubrics, evidence-control materials, calculation worksheets and monitoring templates are provided in Supplementary Files S1–S4. A demonstration assessment using anonymised and aggregated institutional evidence categories yields RDIS = 0.8513, narrowly exceeding the broader institutional assessment candidate threshold under defined assumptions. This result should be interpreted cautiously. It is not regulatory approval, clinical validation, medical-device classification, product certification, universal safety proof or commercial endorsement. Rather, it illustrates how governance readiness can be translated into weighted, auditable and stage-gated system evidence for responsible deployment assessment in high-stakes health-domain institutions.
Keywords: embodied AI; eldercare robotics; AI governance; governance readiness; RDIS; auditability; data governance; human oversight; institutional deployment; regulated deployment infrastructure; nursing homes
-
Introduction
Embodied AI eldercare robotics is moving from research laboratories and technology demonstrations into institutional care environments. In nursing homes and long-term care settings, such systems may navigate shared spaces, interact with residents and caregivers, support reminders and monitoring, process operational or environmental data, and become embedded in routine care workflows. This transition creates a socio-technical systems problem rather than a narrow product-performance problem. A robot that can perform selected care-related tasks is not automatically ready for governed, auditable and institutionally controlled deployment [1-3].
The central issue addressed in this paper is therefore not whether an embodied AI eldercare robot can move, speak, remind, monitor or assist. The more important governance question is whether the combined deployment system can demonstrate sufficient evidence that the robot, institution, staff workflow, data infrastructure, oversight arrangements and lifecycle feedback mechanisms are ready for controlled use. This governability-first question differs from capability-first evaluation: it asks whether the robot is supported by a structured deployment infrastructure rather than by technical promise alone [2,5].
The practical importance of this question is heightened by the nature of institutional eldercare. Care settings involve vulnerable residents, professional caregivers, duty-of-care obligations, personal data, incident reporting, operational continuity and accountability to families, operators and regulators. An embodied AI care robot may show promising mobility, interaction or monitoring functions, yet still fail as a governed system if audit logs are incomplete, staff override procedures are unclear, data flows are not mapped, training evidence is missing, incident closure is undocumented or post-deployment monitoring is absent [3,5,7,9].
This paper proposes RR-Gov™, a quantitative governance-readiness framework for embodied AI eldercare robotics. Its core output is the Regulated Deployment Infrastructure Score (RDIS), a weighted composite candidate score supported by non-substitutable stage-gate thresholds. RDIS integrates governance risk control, compliance confidence, AI auditability, institutional deployability, data governance and governance-adjusted viability. The framework is designed for regulated institutional deployment assessment; it is not clinical validation, regulatory approval, product certification, universal safety proof or commercial product promotion.
The research question is: how can the governance readiness of embodied AI eldercare robots be assessed through a quantitative, auditable and stage-gated framework for regulated institutional deployment? The answer developed here is a socio-technical systems model that treats deployment readiness as an institutional property created by the interaction among robot capability, governance evidence, human oversight, data controls, workflow integration and post-deployment feedback.
Detailed formula definitions, scoring rubrics, evidence-control materials, calculation worksheets and monitoring templates are provided in Supplementary Files S1-S4 to preserve auditability without turning this technical disclosure into an operational handbook.
2.Related Work and Research Gap
A focused literature positioning exercise was conducted to locate RR-Gov™ within research on eldercare robotics, long-term care governance, implementation science, healthcare AI deployment, data ethics, algorithmic auditing and model documentation. The selected comparator papers do not claim the same model; rather, they represent the closest conceptual neighbourhood of the proposed framework. Together, they show that the field has strong descriptive, ethical, policy and implementation foundations, but does not yet provide a compact quantitative governance-readiness score for embodied AI eldercare robots deployed in institutional health-domain environments [1–10].
The eldercare robotics literature establishes that socially assistive robots may support communication, companionship, reminders, monitoring and selected care-related tasks [1,8]. However, role description and deployment mapping do not by themselves answer whether an embodied robot can be governed inside a nursing home or long-term care institution. Governance studies in long-term care robotics highlight policy, adoption, risk and sandbox issues, especially in Singapore’s long-term care context [2]. Implementation research further shows that organisational readiness, staff workflow, training and facility context materially affect whether social robots can be introduced into care settings [3]. These findings support the institutional deployability dimension of RR-Gov™, but they do not provide an integrated RDIS-like scoring architecture.
Ethics and data-governance research supplies another essential foundation. Prior work on robot care ethics identifies dignity, deception, privacy, autonomy, human contact, dependency and substitution-of-care risks [4,10]. Public-health data ethics and healthcare AI translation literature emphasise privacy, public interest, evaluation, regulation, post-market monitoring, bias control and generalisability [5,6]. These studies clarify why care-robot deployment cannot be assessed by technical performance alone. Yet ethical and policy principles often remain qualitative unless they are converted into observable indicators, evidence requirements, audit trails and stage-gated thresholds.
AI auditability and reporting literature provide the third foundation. Algorithmic auditing research explains how internal audit processes, accountable artifacts and reviewable records can reduce accountability gaps [7]. Model-reporting literature demonstrates the value of structured documentation for intended use, limitations and performance boundaries [9]. RR-Gov™ adapts these ideas to embodied eldercare robotics by proposing AI Auditability Score, Governance Event Logging Standard and an RDIS Governance Card. The adaptation is necessary because the assessed object is not a software model alone, but a product-in-setting that includes robot behaviour, staff supervision, resident-facing workflows, data controls and post-deployment feedback.
The resulting research gap is therefore precise. Prior literature has examined robot roles, adoption barriers, ethics, policy governance, healthcare AI translation, data ethics, auditability and documentation. What remains missing is an integrated, weighted and stage-gated governance-readiness model specifically designed to assess whether an embodied AI eldercare robot is supported by sufficient institutional evidence for controlled deployment assessment. RR-Gov™ addresses this gap by converting fragmented governance requirements into RDIS, a composite candidate score supported by non-substitutable critical gates.
The originality claim is intentionally bounded. RR-Gov™ should not be read as asserting that every component is new or that no prior work addresses any related issue. Its contribution is first-definition-type integration: an early structured assessment language for the intersection of embodied AI, eldercare robotics, institutional health systems, auditability, data governance and regulated deployment readiness. This cautious positioning avoids unsupported world-first claims while preserving the manuscript’s central contribution: a quantitative and auditable systems framework for governance-readiness assessment.

3. Definition and System Boundary of RR-Gov
3.1. Framework Definition
RR-Gov™ is defined in this manuscript as a quantitative governance-readiness assessment framework for evaluating whether an embodied AI eldercare robot can be considered supportable for controlled institutional deployment under explicitly defined operating conditions. The central question is not whether a robot can perform isolated functions, but whether its deployment can be justified by sufficient governance evidence across risk control, compliance readiness, auditability, data governance, human oversight, workflow compatibility and institutional deployability [2,5,7,9]. In this sense, RR-Gov™ shifts the assessment lens from pure functionality to governability. It treats the deployment of embodied AI care robots as a socio-technical systems problem in which technical performance, organisational practice and governance safeguards must operate together [1,3].
3.2. Scope and System Boundary
RR-Gov™ should therefore not be interpreted as a regulatory approval mechanism, a clinical validation framework, a medical-device certification tool, a universal safety claim or a substitute for professional judgment. Rather, it is a structured assessment pathway that helps institutions, technology providers and governance reviewers determine whether a deployment scenario may be treated as a governance-readiness candidate under defined evidence boundaries [7,9]. The resulting RDIS score is a boundary-conditioned interpretation, not proof of effectiveness or clearance. This distinction is important because a care robot may appear technically capable while remaining unsuitable for deployment if privacy safeguards are weak, audit logs are incomplete, escalation pathways are unclear or human supervision is poorly defined.
The system boundary of RR-Gov™ contains four interacting layers, summarized in Figure 1. The technical layer covers robot functions, sensing, navigation, interaction, reliability and task-level operating assumptions. The institutional layer covers staffing, workflow integration, training, supervision arrangements, incident response and operational continuity. The governance layer covers compliance controls, privacy and data-protection safeguards, accountability allocation, audit-trail capability and reviewability. The feedback layer covers post-deployment monitoring, corrective action, recalibration and periodic reassessment. Defining these layers makes clear that the object of assessment is not the robot alone but the deployment system composed of the robot, the institution, the governance controls and the review loop [2,5].

3.3. Decision Levels and Non-Substitutability
Within this boundary, RR-Gov™ separates three decision levels. The first is technical demonstration readiness, which asks whether specified functions can be shown under controlled conditions. The second is supervised institutional pilot readiness, which asks whether a site can introduce the robot with documented controls, role assignments, escalation rules and auditable records. The third is broader institutional assessment, which asks whether the governance evidence is sufficiently mature, repeatable and reviewable to support expansion beyond a narrow pilot. RR-Gov™ is primarily designed for the second and third levels. It does not treat laboratory functionality alone as sufficient evidence for institutional deployment [1,7].
A key design principle is the non-substitutability of critical governance gates. Composite scores are useful for summarising multiple dimensions, but in high-sensitivity care settings a strong score in one domain should not offset a critical weakness in another. High governance-adjusted viability, for example, cannot compensate for poor privacy controls; good workflow compatibility cannot compensate for missing auditability; and promising technical functionality cannot compensate for weak human-oversight arrangements [2,5,9]. RR-Gov™ therefore combines a weighted score with minimum stage-gate thresholds. This protects the framework from producing falsely reassuring aggregate scores and preserves its role as a reviewer-safe governance instrument rather than a promotional metric.
3.4. Governance Card and Interpretation Boundary
The reporting artifact generated by the framework is the RR-Gov™ Governance Card. This card records the assessed deployment boundary, intended use, evidence categories, component scores, stage-gate outcomes, residual limitations and remediation priorities. Table 2 summarises the reviewer-safe interpretation boundary of the framework. Together, the figure, table and Governance Card make the boundary conditions explicit: RR-Gov™ assesses governance readiness for a defined deployment scenario, not universal deployability. Its purpose is to support structured institutional review, transparent documentation and controlled implementation planning under auditable conditions [3,7].

4. RDIS Quantitative Model
4.1. Model Objective and Analytical Boundary
The core output of RR-Gov™ is the Regulated Deployment Infrastructure Score (RDIS), a composite governance-readiness candidate score for assessing whether an embodied AI eldercare robot is supported by sufficient institutional, audit, data-governance and oversight evidence for controlled deployment assessment. This section restores the internal logic of the model while keeping the technical paper readable for public reference and future peer review: the main text explains the architecture, formula, weighting rationale, evidence-to-score conversion, stage-gate logic and interpretation boundary; the detailed formula dictionary, calculation worksheets and monitoring templates are provided in the supplementary files.
The unit of analysis is the deployment system, not the robot alone. The assessed system includes robot functions, institutional workflow, staff supervision, human override procedures, audit trails, incident escalation, data-governance controls, training evidence and lifecycle feedback. This systems-level boundary is essential because eldercare robotics literature shows that care robots may demonstrate useful assistive functions, yet long-term care deployment still depends on organisational readiness, ethics, privacy protection, human oversight and implementation context [1-4,8,10].
RDIS is not a regulatory approval mechanism, medical-device classification conclusion, clinical validation framework, product certification, safety guarantee or commercial valuation model. It is a structured analytical method for converting governance evidence into a candidate readiness score under defined assumptions. Source-record confirmation and evidence-control boundaries are addressed in Supplementary File S1 where applicable, while detailed formula definitions, scoring rubrics, demonstration calculations, stage-gate logic and lifecycle monitoring templates are provided in Supplementary Files S2-S4 [5,6].
4.2. Overall RDIS Architecture and Composite Formula
RDIS integrates six governance components: adjusted governance risk index (GRI′), compliance confidence factor (CCF), AI auditability score (AAS), institutional deployability score (IDS), data governance score (DGS) and governance-adjusted viability score (MVS). The baseline composite model is expressed as follows:
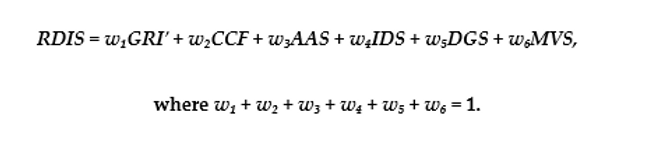
For the demonstration calculation, the positive-form risk-control score is converted as GRI′ = 1 - GRI/5. Thus, a lower underlying governance-risk value produces a higher positive-form readiness score; for example, GRI = 0.9675 gives GRI′ = 1 - 0.9675/5 = 0.8065.
The formula is retained because it represents the central methodological contribution. Detailed sub-formulas for GRI, CCF, AAS, GELS, IDS, DGS, MVS and monitoring indicators are placed in Supplementary Files S2-S4 so the main text remains a systems paper rather than a mathematical handbook.
4.3. Component Definitions and Baseline Weighting
GRI′ is the positive-form governance risk-control component. It converts underlying risk exposure into a readiness direction so that a higher value represents stronger risk control. CCF measures the credibility of the compliance pathway, including standards alignment, privacy readiness, ethics or institutional review clarity, incident reporting and post-deployment monitoring. AAS measures whether task records, AI-output records, access logs, incident logs, human override records and resolution records are complete, traceable and reviewable. IDS measures whether the robot can be introduced into a real care institution with technical reliability, workflow compatibility, staff training, governance procedures and human-robot collaboration readiness. DGS measures lifecycle data governance, including minimisation, encryption, access control, anonymisation or pseudonymisation, transfer control, retention and breach response. MVS is retained only as governance-adjusted viability, meaning practical adoption and scalability viability after governance safeguards have been satisfied; it is not a revenue, pricing or investment-return variable. International safety, AI risk-management, AI management-system and medical-software governance references are used as anchoring materials for standards alignment and risk interpretation; they do not imply certification, regulatory clearance or compliance approval.
The baseline weighting used in this manuscript is 20% for GRI′, 20% for CCF, 20% for AAS, 15% for IDS, 15% for DGS and 10% for MVS. This weighting is intentionally conservative and is presented as a baseline governance-calibration proposal rather than as a universally fixed weighting scheme. Risk control, compliance confidence and auditability receive the highest weights because embodied AI systems operate in physical environments involving vulnerable residents, staff workflow, personal data and post-event accountability. IDS and DGS receive substantial weights because real-world deployment requires workflow fit and data lifecycle control. MVS receives the lowest weight because adoption viability should matter only after minimum governance safeguards are satisfied. Alternative weighting structures may be calibrated through expert review, Delphi assessment, analytic hierarchy process or jurisdiction-specific governance consultation, and future validation should test whether RDIS classification remains materially stable under reasonable weighting variations.

4.4. Evidence-to-Score Conversion and Calculation Workflow
The evidence-to-score conversion uses a five-point readiness rubric: 0, 0.25, 0.50, 0.75 and 1.00. A score of 0 means no evidence or not prepared; 0.25 indicates initial planning; 0.50 indicates partial evidence; 0.75 indicates substantial preparedness with minor gaps; and 1.00 indicates documented, implemented, auditable and reviewable evidence within the defined boundary. This simple rubric allows institutions to attach documentary evidence while maintaining scoring consistency. The detailed rubric is provided in Supplementary File S2.
Component scores such as 0.88, 0.87 or 0.86 are therefore not inconsistent with the five-point rubric. They are aggregated results from multiple sub-indicators scored on the five-point scale and then averaged or weighted within each component, as detailed in Supplementary File S2.
The calculation workflow contains six practical steps: define the deployment boundary; map evidence to the six RDIS components; score each component using the readiness rubric; calculate the composite RDIS; apply non-substitutable stage gates; and continue post-deployment monitoring. This workflow makes RR-Gov™ a lifecycle governance model rather than a one-time checklist. Override frequency, incident escalation, audit-log completeness, compliance closure, corrective-action resolution and remediation status should be periodically reviewed and should trigger recalibration if the deployment environment changes [5,7,9].
4.5. Non-Substitutable Stage-Gate Logic
The most important methodological safeguard is non-substitutability. A composite score alone may allow strength in one domain to conceal failure in another. That logic is unsuitable for embodied AI eldercare robotics. RR-Gov™ therefore applies critical stage-gate thresholds after the composite RDIS is calculated. A system should not proceed as a broader institutional assessment candidate if minimum evidence thresholds for risk control, compliance confidence, auditability, data governance, institutional deployability or human oversight are not satisfied. In practical terms, safety, privacy, auditability, data governance and human oversight failures cannot be offset by governance-adjusted viability.
Human oversight is treated as an embedded non-substitutable governance requirement across GRI′, CCF, AAS and IDS rather than as a separate standalone gate in Table 4. A deployment scenario with weak human override, unclear escalation or incomplete supervision evidence should therefore fail remediation review even if the aggregate RDIS appears acceptable.

4.6. Demonstration Result and Interpretation Boundary
A demonstration score such as RDIS = 0.8513 should be read cautiously. It indicates that, under the stated assumptions, evidence boundary and baseline weighting, the assessed deployment may be treated as a governance-readiness candidate for broader institutional assessment. It does not mean that the robot is approved, certified, clinically validated, automatically deployable or free from further local review. The arithmetic audit trail, component scores and stage-gate worksheet are provided in Supplementary File S3, while the monitoring indicators and RDIS Governance Card are provided in Supplementary File S4.
4.7. Supplementary Materials and Calibration Boundary
The supplementary structure is part of the model design. S1 documents the data-validation and evidence-control boundary; S2 defines the formula dictionary and scoring rubric; S3 provides the demonstration calculation and stage-gate worksheet; and S4 provides lifecycle monitoring indicators and the RDIS Governance Card. This separation keeps the technical disclosure readable while preserving mathematical and evidentiary detail for future review and replication.
Because RR-Gov™ is proposed as an early integrated governance-readiness framework, its weights, thresholds and monitoring indicators should be treated as calibratable. Future work should test the stability of RDIS classifications across alternative weights, longer deployment periods, independent institutions, different robot functions and jurisdiction-specific governance requirements. The present model therefore contributes a structured assessment language and auditable workflow, not a final universal certification rule.

5. Institutional Evidence and Demonstration Assessment
5.1. Evidence Boundary and Demonstration Purpose
The purpose of this section is to explain how RR-Gov™ converts institutional evidence into an auditable demonstration assessment. In the previous section, RDIS was defined as the quantitative governance-readiness model. This section answers a different question: where do the component scores come from, and how should a demonstration result be interpreted? The validation logic is therefore intentionally narrower than a full clinical, regulatory or commercial evaluation. It does not claim that an embodied AI eldercare robot is universally safe, clinically effective, regulatorily approved or ready for unrestricted deployment. Instead, it demonstrates how anonymised, aggregated and evidence-controlled institutional materials may be mapped to the RDIS scoring architecture under a defined assessment boundary [1-6].
The evidence boundary is important because care robots operate inside socio-technical institutions rather than abstract laboratory settings. Relevant evidence may include deployment procedures, site-readiness records, workflow observations, staff training records, incident-escalation procedures, audit-log samples, access-control evidence, data-protection controls, maintenance records and governance-review notes. Identifiable resident records, identifiable staff records, raw photographs, signatures, facility-sensitive operational logs and confidential institution-specific materials should not be published in this technical preprint / technical disclosure. Source-record confirmation and evidence-control limitations are addressed in Supplementary File S1.
5.2. Institutional Evidence Architecture
RR-Gov™ treats institutional validation as an evidence architecture rather than as a single validation report. This structure reflects the practical reality that a robot may pass selected functional tests but still be unsuitable for deployment if auditability, privacy control, staff supervision or incident governance is weak. The validation layer therefore links each evidence category to one or more RDIS components and asks whether the evidence is observable, documented, auditable and reviewable. This is consistent with implementation-science and healthcare AI governance literature, which emphasises that deployment performance depends on organisational context, monitoring, accountability and post-deployment review rather than technical capability alone [2,3,5,7,9].

5.3. Evidence-to-Score Conversion Logic
The evidence-to-score conversion follows the five-point readiness rubric retained in Supplementary File S2. A score of 0 indicates no evidence or no preparation; 0.25 indicates initial planning; 0.50 indicates partial evidence with material gaps; 0.75 indicates substantial preparation with minor gaps; and 1.00 indicates documented, implemented, auditable and reviewable evidence within the defined boundary. This conversion method is designed to prevent purely narrative claims from being treated as equivalent to reviewable evidence. Where evidence is incomplete, uncertain, untested or not independently reviewable, the score should be reduced. Where evidence exists only in design documents without institutional use, the score should generally remain below pilot-level readiness.
This technical preprint / technical disclosure does not reproduce validation-level formulas such as workflow coverage, caregiver training rate, operational reliability, override frequency, incident escalation, compliance closure or lifecycle monitoring. Those templates are retained in the supplementary materials so that the article remains readable as a Systems paper. In the main text, the essential point is that each component score must be traceable to a defined evidence category, a scoring rule, a responsible evidence owner and a remediation pathway. This turns the assessment from a subjective checklist into a structured governance record.
5.4. Demonstration Score and Stage-Gate Interpretation
Using the baseline RDIS architecture, the demonstration calculation yields a final RDIS of 0.8513. The component-level scores and arithmetic audit trail are reported in Supplementary File S3. This value should be interpreted as narrowly above the broader institutional assessment threshold, not as a universal approval conclusion. It indicates that, under the stated assumptions, evidence boundary and baseline weighting, the assessed deployment may be considered a governance-readiness candidate for broader institutional assessment, subject to local approvals, institutional review and continuing monitoring.
The stage-gate interpretation is as important as the composite score. RR-Gov™ does not allow a strong score in one domain to compensate for unresolved failures in another. Safety, compliance confidence, auditability, data governance, institutional deployability and human oversight remain non-substitutable safeguards. Accordingly, RDIS = 0.8513 is meaningful only if the minimum critical gates are also satisfied. If material weaknesses in safety, privacy, auditability, escalation or data-governance controls remain unresolved, the appropriate conclusion would be remediation rather than progression, even if the aggregate score appears acceptable [6,7].
5.5. Interpretation Boundary and Future Validation
The Section 5 demonstration should be read as a framework demonstration and not as final validation of a universal scoring system. It does not establish clinical effectiveness, resident outcome improvement, medical-device clearance, legal compliance in all jurisdictions, procurement suitability or financial return. It also does not replace professional care judgment, institutional governance review, regulator interpretation or site-specific risk assessment. Its contribution is to show how RR-Gov™ can connect governance theory, institutional evidence, scoring logic and stage-gated interpretation in a single auditable workflow.
Future validation should test the stability and reliability of this evidence-to-score pathway across multiple institutions, longer deployment periods, different resident profiles, different robot functions and independent assessor groups. Additional work should include inter-rater reliability testing, sensitivity analysis of component weights, jurisdiction-specific regulatory review and comparison across different institutional resource settings and care-delivery environments. Until such validation is completed, the demonstration result should be presented as an early governance-readiness example under defined assumptions. This cautious interpretation strengthens the academic credibility of RR-Gov™ by avoiding overclaiming while preserving the model’s practical value for regulated deployment assessment.
6. Results
6.1. Demonstration Result Overview
A demonstration assessment was conducted using anonymised and aggregated institutional evidence categories within the RR-Gov™ model boundary. The purpose of this results section is not to prove universal deployment readiness, but to show how the RDIS framework converts evidence-controlled component scores into a stage-gated governance-readiness interpretation. This distinction follows the systems-oriented logic of the paper: the assessment concerns the deployment infrastructure surrounding an embodied AI eldercare robot, not the technical performance of the robot alone [1-4,8,10].
The final demonstration result is RDIS = 0.8513. This places the assessed deployment scenario narrowly above the broader institutional assessment candidate threshold of 0.85. The narrow margin is important. It supports a threshold-positive governance-readiness interpretation, but it also prevents overstatement. The result should therefore be read as a candidate finding requiring continued monitoring, local regulatory calibration, independent validation and post-deployment governance controls [5-7].
6.2. Component-Level Score Summary
The final RDIS result should not be interpreted only as a single aggregate value. Each component carries a distinct governance meaning. A high aggregate score would be insufficient if a critical domain such as compliance confidence, auditability, data governance or institutional deployability remained materially weak. The component-level outputs are summarised in Table 6; the arithmetic audit trail, detailed component scoring worksheet and MVS governance-adjusted viability subscore construction are provided in Supplementary File S3.

6.3. Stage-Gate Result
The stage-gate evaluation indicates that the core gate variables satisfy minimum thresholds. The scenario satisfies the aggregate RDIS gate, the compliance confidence gate, the AI auditability gate, the institutional deployability gate and the data-governance gate. It also maintains a controlled GRI profile within the demonstration boundary. These results support classification as a broader institutional assessment candidate rather than a final deployment approval.
The stage-gate logic is methodologically important because it prevents one strong domain from concealing weakness in another. If a deployment scenario achieved a high aggregate RDIS but failed auditability or data governance, RR-Gov™ would classify it as requiring remediation. This built-in governance brake differentiates RDIS from a superficial scoring exercise and aligns the framework with systems-level risk management and accountable AI governance principles [5,7,9].

6.4. Interpretation of the RDIS = 0.8513 Result
The RDIS = 0.8513 result should be interpreted cautiously. It indicates that, under the stated assumptions, evidence boundary and baseline weighting, the assessed system may be treated as a governance-readiness candidate for broader institutional assessment. It does not mean that the robot is approved, certified, clinically validated, automatically deployable or free from further local review. This interpretation is consistent with the evidence-controlled approach used in Section 5 and with the supplementary audit trail in S1-S4.
The component profile also suggests practical priorities for future work. CCF, AAS, IDS and DGS are relatively strong, indicating that the demonstration is supported by compliance-readiness, auditability, institutional-fit and data-governance evidence. GRI′ indicates controlled residual risk rather than risk elimination. MVS is acceptable but relatively lower, suggesting that longer observation should strengthen utilisation evidence, maintenance readiness, service continuity and institutional adoption patterns. The result therefore supports staged assessment, not unconditional expansion.
6.5. Result Boundary
These results are boundary-specific. They are based on anonymised and aggregated evidence categories and should not be generalised as proof of universal safety, clinical effectiveness, medical-device clearance or cross-institutional deployability. Broader claims would require multi-site validation, independent assessor review, longer monitoring periods, sensitivity analysis of weights and thresholds, inter-rater reliability testing and jurisdiction-specific governance consultation. The contribution of the results is therefore methodological and evidentiary: they demonstrate that RR-Gov™ can translate structured institutional evidence into an auditable, stage-gated governance-readiness interpretation for embodied AI eldercare robotics [2,3,5,7,9].
7. Discussion
7.1. Principal Findings
The results of this study support the central proposition of RR-Gov™: regulated deployment of embodied AI eldercare robotics should be evaluated as a socio-technical governance infrastructure problem rather than as a robot-performance question alone. The demonstration result reported in the Results section indicates that the assessed deployment scenario reaches a threshold-positive RDIS outcome, but this should be interpreted as a governance-readiness candidate finding under a defined evidence boundary. The result is meaningful because it shows that risk control, compliance confidence, auditability, institutional deployability, data governance and governance-adjusted viability can be evaluated together in one structured framework. At the same time, the narrow margin above the broader assessment threshold reinforces the need for continuing monitoring, local regulatory calibration and post-deployment governance rather than unconditional deployment claims [1-6].
7.2. Contribution to Systems and Governance Literature
RR-Gov™ contributes to Systems research by positioning eldercare robotics as an interconnected deployment system involving technology, institutional workflow, staff supervision, audit records, personal-data controls, incident escalation and lifecycle feedback. This differs from studies that mainly examine whether older adults accept socially assistive robots, whether a robot performs a care-related task, or whether implementation barriers exist in isolation [1,3,8,10]. Those contributions remain important, but they do not by themselves provide a quantitative governance-readiness architecture. RR-Gov™ addresses this gap by linking a composite RDIS model with stage-gate logic, evidence-to-score conversion and supplementary audit templates.
The framework also extends healthcare-AI governance literature. Prior work has emphasised evaluation, regulation, post-market monitoring, transparency, model reporting, public-health data ethics and algorithmic auditing [5-9]. RR-Gov™ applies those concerns to embodied AI robots operating in physical eldercare institutions. The contribution is therefore not merely the production of a numerical score. Its value lies in defining how governance evidence should be organised, how critical domains should be treated as non-substitutable, and how a deployment decision can move from broad principles to auditable evidence. This is why the manuscript uses cautious first-definition-type and early integrated framework language rather than an absolute novelty claim.
7.3. Auditability, Traceability and Stage-Gate Governance
One of the most important implications is that auditability becomes a deployment condition rather than a desirable add-on. In embodied AI eldercare robotics, system actions may involve navigation, reminders, alerts, interaction support, staff override, task scheduling or data access. If such actions cannot be reconstructed through logs, timestamps, actors, data objects, risk levels, outcomes and closure status, the institution cannot reliably govern the deployment. The AAS and GELS components therefore operationalise transparency and accountability into reviewable records, while the RDIS Governance Card provides a concise reporting artefact for institutional review [7,9].
The stage-gate design is equally important. A simple weighted score may allow strengths in one area to conceal weaknesses in another. RR-Gov™ avoids this by requiring minimum performance in critical domains such as compliance confidence, auditability, institutional deployability, data governance and underlying risk control. This non-substitutability principle is especially relevant in care settings because vulnerable residents, frontline caregivers, facility operators and data subjects may be affected by both technical failure and governance failure. A high adoption or viability signal should not offset unresolved privacy, safety, auditability or oversight weaknesses.
7.4. Practical Implications for Institutions, Developers and Reviewers
For care institutions, RR-Gov™ provides a practical language for moving from pilot enthusiasm to disciplined deployment review. Rather than asking only whether a robot may reduce workload or improve service experience, an institution can ask whether the evidence is sufficient for controlled assessment: Are responsibilities defined? Are staff trained? Are overrides recorded? Are incidents escalated? Are access controls documented? Are remediation actions closed? These questions help institutions convert a technology trial into a governance-managed deployment pathway.
For developers, the framework indicates what should be built into the product and deployment package from the beginning. Audit logs, access controls, role-based permissions, incident categories, override functions, training materials, data-retention settings and support procedures should not be treated as post-sale documentation. They are part of the deployment-readiness infrastructure. For regulators, procurement reviewers and governance committees, RDIS can provide a structured summary for internal risk review, pilot approval discussions, procurement due diligence and post-deployment surveillance planning. However, it should support judgment rather than replace legal, regulatory, institutional or professional decision-making.

7.5. Methodological Boundaries, Limitations and Future Validation
Several limitations require clear interpretation. First, the RDIS demonstration is based on anonymised, aggregated and evidence-controlled institutional categories rather than a randomised clinical trial. It does not establish clinical effectiveness, resident outcome improvement, medical-device classification, regulatory approval, legal compliance in all jurisdictions or cross-institutional deployment clearance. Second, the baseline weighting structure is a governance-calibration proposal. Future work should test alternative weights through expert review, Delphi assessment, analytic hierarchy process, jurisdiction-specific regulatory consultation and sensitivity analysis. Third, scoring reliability depends on the quality, completeness and reviewability of source evidence. Weak evidence should reduce scores even when the model structure appears complete.
Future research should therefore proceed in four directions. Multi-institutional studies should examine whether the same scoring structure remains stable across different institutional resource settings and care-delivery environments. Longer deployment periods should test whether initial readiness is maintained through incident review, human override trends, compliance closure, staff adaptation, maintenance reliability and data-governance performance. Independent assessor panels should evaluate inter-rater reliability and reduce the risk of author-side scoring bias. Finally, future work should examine how the RDIS approach can be aligned with established institutional risk-management, AI-management, data-governance and quality-improvement processes, without treating the present framework as a universal certification rule.
Overall, the discussion confirms that RR-Gov™ should be understood as an early integrated and auditable deployment-readiness framework. It does not ask whether embodied AI eldercare robots should be accepted or rejected in abstract terms. It asks whether a defined deployment system has enough evidence, controls, auditability and lifecycle governance to proceed responsibly to the next assessment stage. This systems-oriented framing is the main contribution of the paper and the reason the detailed formulas, worksheets and monitoring cards are placed in supplementary files while the technical preprint / technical disclosure preserves a reader-friendly academic structure for future peer review.
8. Practical Implementation Pathway and Future Validation Agenda
8.1. Deployment Boundary Definition
RR-Gov™ is intended to be used as a structured governance-assessment pathway rather than as a one-time numerical score. The first operational step is to define the deployment boundary: active robot functions, resident or unit scope, data categories, staff accountability, supported tasks, escalation rules and excluded uses. Without this boundary, any readiness score would be ambiguous, because the same robot may carry different governance risks when used for supervised wayfinding, night-time monitoring, reminders, mobility support or resident-facing interaction. This boundary-first logic aligns with systems-oriented AI risk management, where the assessed object is the product-in-setting rather than the technology in isolation [5].
8.2. Evidence Assembly and Governance Card Output
After the boundary is defined, the institution should assemble evidence across the six RDIS components. Evidence should include governance records, training records, workflow maps, incident escalation routes, human-override procedures, audit-log samples, data-flow descriptions, maintenance controls and post-deployment monitoring plans. The practical output should be an RDIS Governance Card identifying the robot version, intended-use boundary, site type, data categories, active AI functions, oversight model, component scores, stage-gate result, evidence sources, unresolved gaps and remediation actions. This card is inspired by model-reporting literature but is adapted for embodied care robotics: it reports the deployment system around the robot, not only the technical model [7,9].
8.3. Stage-Gated Implementation Pathway
The implementation pathway should proceed through staged governance decisions rather than a binary approval narrative. Stage 1 is boundary definition and pre-deployment governance mapping. Stage 2 is controlled pilot readiness, where training, supervision, incident reporting and audit logging are tested in a limited environment. Stage 3 is broader institutional assessment, where evidence becomes repeatable across shifts, units or comparable care settings. Stage 4 is lifecycle monitoring, where override frequency, incident escalation, audit-log completeness, compliance closure and recalibration notes are periodically reviewed. This pathway prevents RDIS from being misunderstood as a simple product endorsement. It identifies what level of governed use may be supportable under the current evidence boundary.

8.4. Future Validation Agenda
The future validation agenda has been discussed in Section 7.5. In practical terms, these studies should involve multi-institutional field testing across different care-delivery settings, inter-rater reliability assessment, sensitivity analysis of component weights and thresholds, longitudinal lifecycle monitoring and alignment with established risk-management and AI-management processes [5,7,9]. The present section therefore does not repeat those research directions in detail; it records them as a formal part of the practical implementation pathway.
8.5. Boundary of Practical Use
The practical pathway also clarifies why this technical preprint / technical disclosure should not reproduce every operational formula. Readers and future reviewers need to understand the framework, boundary, stage-gate logic and auditability pathway; detailed worksheets belong in supplementary files to preserve reproducibility without turning the article into an implementation manual. RR-Gov™ may support procurement review, institutional risk review and pilot-governance discussion, but it should not replace legal review, regulatory interpretation, clinical evaluation, institutional approval or professional care judgment. Its contribution is to provide an early integrated, measurable and auditable assessment language for regulated socio-technical deployment. The value of RR-Gov™ is not that it ends the governance debate, but that it gives that debate a structured, evidence-linked and systems-oriented pathway [2,5,7].
Conclusion
RR-Gov™ provides a quantitative and auditable governance-readiness framework for assessing embodied AI eldercare robotics as regulated socio-technical deployment systems. By integrating governance risk control, compliance confidence, AI auditability, data governance, institutional deployability, governance-adjusted viability and non-substitutable stage-gate thresholds, the RDIS model converts fragmented governance requirements into a structured assessment score.
The demonstration result of RDIS = 0.8513 illustrates how the model may classify a defined deployment scenario as a governance-readiness candidate under specified evidence boundaries and baseline weighting assumptions. This result should be interpreted cautiously. It does not constitute regulatory approval, clinical validation, medical-device classification, product certification, safety guarantee or universal deployment clearance. Rather, it indicates that the assessed deployment scenario may support broader institutional assessment subject to local regulatory interpretation, institutional approval, continued monitoring, data-governance controls and post-deployment review.
Future research should validate RR-Gov™ across multiple institutions, longer deployment periods, different robot functions, regulatory environments and care-delivery settings. Further work should also test inter-rater reliability, sensitivity of component weights and thresholds, and the stability of RDIS classifications under independent expert and empirical validation.
Declarations
Prior Public Version Disclosure
This company-led technical preprint / technical disclosure version is made available for transparency, version control and public reference. It has not undergone independent peer review. If a substantially revised manuscript is later submitted to a peer-reviewed journal, this public version and DOI/URL should be disclosed to the target journal in accordance with its editorial policy.
Author Contributions
Conceptualization, Jian Zhang; methodology, Jian Zhang, Hon Hsiang Ong and Xin Zhao; governance framework development, Jian Zhang, Hon Hsiang Ong, Xin Zhao, Wentao Zhao, Wenqun Guo, Qiang Huang and Weijie Tan; institutional workflow interpretation and documentation review, Wentao Zhao, Wenqun Guo, Qiang Huang and Weijie Tan; robotics deployment context and technical interpretation, Tingting Shen, Tian Shen and Chunqiu Yan; evidence coordination and supplementary documentation, Tingting Shen, Tian Shen, Chunqiu Yan, Hon Hsiang Ong and Xin Zhao; writing—original draft preparation, Jian Zhang, Hon Hsiang Ong and Xin Zhao; writing—review and editing, all authors; supervision, Jian Zhang. All authors have read and approved this technical preprint / technical disclosure version.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable. This manuscript presents a governance-readiness assessment framework and modelling study. It does not report a clinical trial, clinical intervention, medical treatment evaluation or human-subject biomedical research. The evidence categories discussed in the manuscript are anonymised, aggregated or governance-level records used for framework demonstration and evidence-boundary analysis. Any future empirical validation involving human participants, identifiable personal data, resident-level records, clinical evaluation or interventional deployment should obtain appropriate ethics, consent, institutional, data-protection and regulatory review.
Informed Consent Statement
Not applicable. No personally identifiable resident data, identifiable medical records, biometric identification data or individual clinical decision data are disclosed in this manuscript.
Data Availability Statement
The supporting evidence categories are anonymised, aggregated or retained internally under access-controlled conditions. Identifiable source records, signatures, photographs, resident-related data, staff-identifiable materials and institution-specific operational records are not publicly disclosed. Anonymised summaries and evidence-control materials may be made available by the corresponding author upon reasonable request, subject to institutional approval, confidentiality requirements and applicable data-protection obligations.
Conflicts of Interest
Several authors are affiliated with AJJ Healthcare Management Pte. Ltd. and Hangzhou Huaxi Intelligent Technology Co., Ltd., which are involved in healthcare technology, robotics-related deployment activities or related governance documentation. The RR-Gov™ framework is proposed as an academic governance-readiness assessment framework and should not be interpreted as regulatory approval, clinical validation, medical-device certification, commercial product certification, investment recommendation or universal deployment clearance. The authors declare that the manuscript has been prepared for academic analysis and framework development, and that the interpretation of RDIS remains subject to independent review, local regulation and institutional governance requirements.
Declaration of AI-Assisted Language and Editorial Support
AI-assisted tools were used during manuscript preparation to support English language editing, grammar refinement, formatting consistency, table organisation and structural clarity. The underlying research framework, field observations, operational evidence logic, validation design, model calculations, references, interpretation and conclusions were reviewed, verified and approved by the authors. No AI-assisted tool was used to generate original field data, fabricate source records, create unsupported references, replace institutional confirmation, perform independent research judgment or assume authorship responsibility.
References
[1] Abdi, J.; Al-Hindawi, A.; Ng, T.; Vizcaychipi, M.P. Scoping review on the use of socially assistive robot technology in elderly care. BMJ Open 2018.
[2] Tan, S.Y.; Taeihagh, A. Governing the adoption of robotics and autonomous systems in long-term care in Singapore. Policy and Society 2021.
[3] Koh, W.Q.; Felding, S.A.; Budak, K.B.; Toomey, E.; Casey, D. Barriers and facilitators to the implementation of social robots for older adults and people with dementia. BMC Geriatrics 2021.
[4] Deusdad, B.A. Ethical implications of using robots in dementia care. Frontiers in Psychiatry 2024.
[5] Kelly, C.J.; Karthikesalingam, A.; Suleyman, M.; Corrado, G.; King, D. Key challenges for delivering clinical impact with artificial intelligence. BMC Medicine 2019.
[6] Vayena, E.; Salathe, M.; Madoff, L.C.; Brownstein, J.S. Ethical challenges of big data in public health. PLOS Computational Biology 2015.
[7] Raji, I.D.; Smart, A.; White, R.N.; Mitchell, M.; Gebru, T.; Hutchinson, B.; Smith-Loud, J.; Theron, D.; Barnes, P. Closing the AI accountability gap: defining an end-to-end framework for internal algorithmic auditing. ACM FAccT 2020.
[8] Aymerich-Franch, L.; Ferrer, I. Socially assistive robots’ deployment in healthcare settings: a global perspective. arXiv 2021.
[9] Mitchell, M.; Wu, S.; Zaldivar, A.; Barnes, P.; Vasserman, L.; Hutchinson, B.; Spitzer, E.; Raji, I.D.; Gebru, T. Model Cards for Model Reporting. ACM FAccT 2019.
[10] Sharkey, A.; Sharkey, N. Granny and the robots: Ethical issues in robot care for the elderly. Ethics and Information Technology 2012.